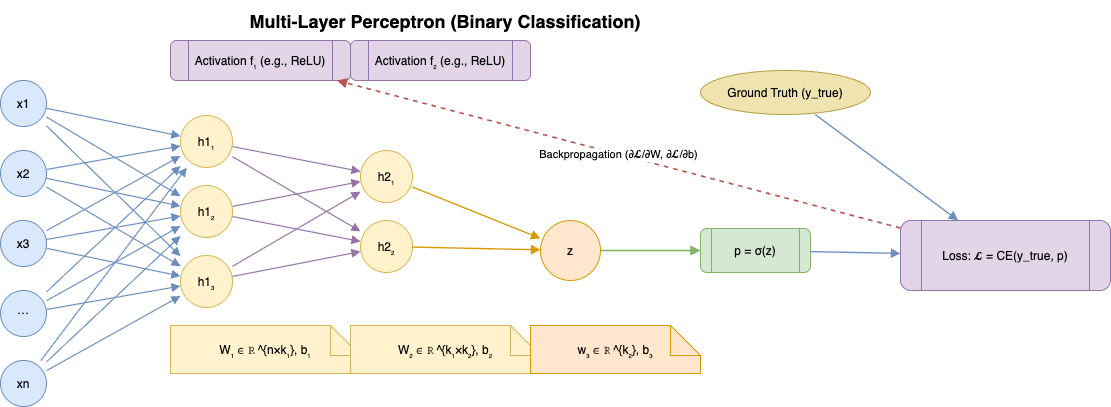
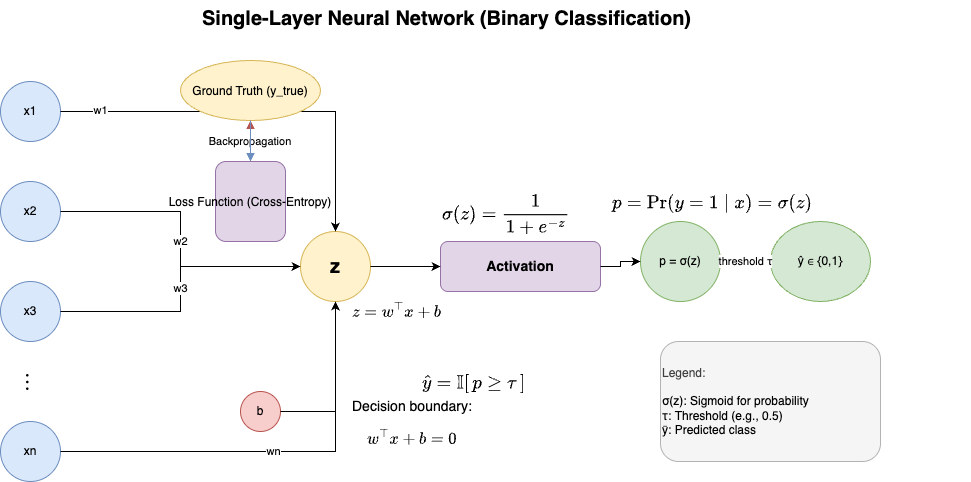
De Morgan’s Law
\[\overline{AB} = \overline{A} + \overline{B}\] \[\overline{A + B} = \overline{A}\,\overline{B}\]Boolean Arithmetic (Combinational Logic)
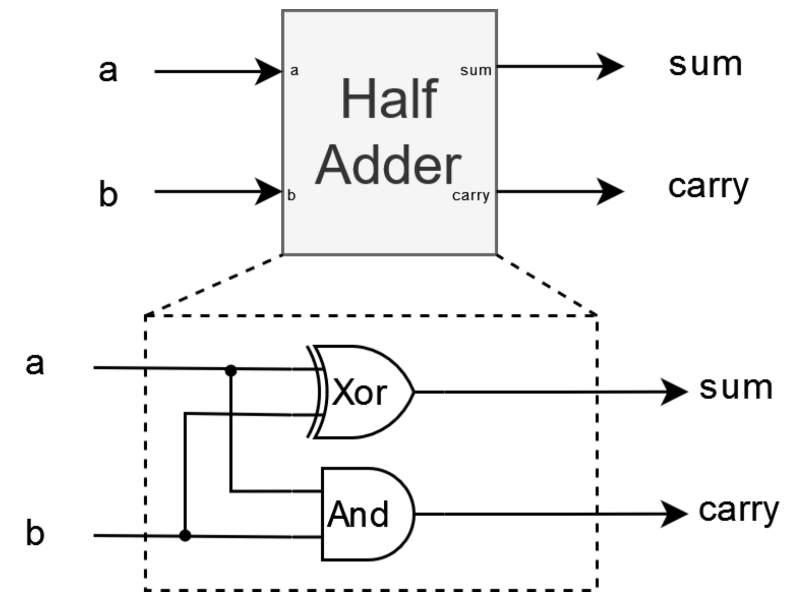
Half Adder
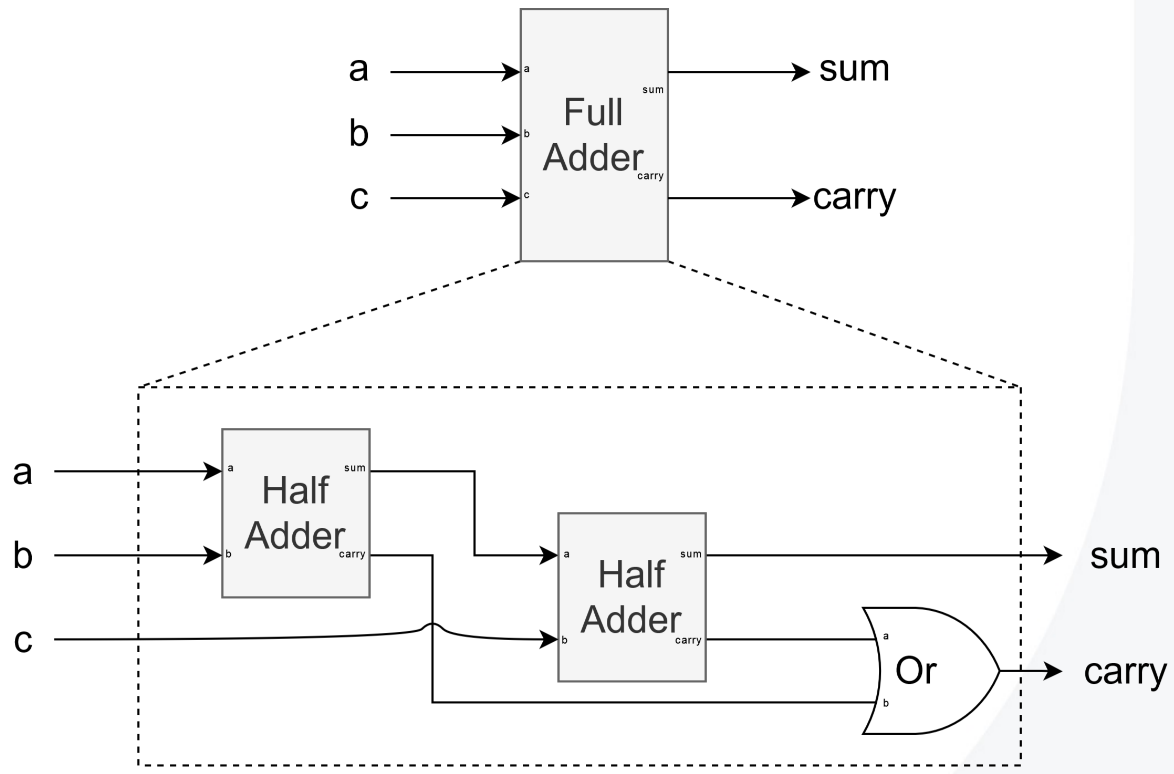
Full Adder
Two’s Complement
Quick Flow
1
2
Decimal → (abs) → bin → invert → +1 → Two’s complement
Binary → (MSB=1?) → invert → +1 → decimal → negative
Binary → Decimal
Concept
1
2
3
4
5
6
7
8
9
10
11
12
13
14
if MSB = 0 → positive
normal binary value
if MSB = 1 → negative
invert bits → add 1 → decimal → add minus sign
Example:
11101100₂
invert → 00010011
+1 → 00010100 = 20
→ -20₁₀
Formula
\[\text{Range} = [-2^{n-1},\, 2^{n-1} - 1]\] \[\text{Decimal} = -b_{n-1} \times 2^{n-1} + \sum_{i=0}^{n-2} b_i \times 2^i\]Example via Formula
1
2
3
4
5
6
Directly convert a binary number to decimal using the formula:
11101100₂
= -1×128 + (1×64 + 1×32 + 0×16 + 1×8 + 1×4 + 0×2 + 0×1)
= -128 + 108
= -20₁₀
Decimal → Binary
Concept
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
choose bit width (ex, 8 bits)
if positive:
normal binary → pad zeros
if negative:
abs(decimal) → binary → invert → add 1
Example:
-20
20 → 00010100
inv → 11101011
+1 → 11101100
Example: Positive via Long Division
1
2
3
4
5
6
7
8
9
10
11
Example, 20₁₀, target width 8 bits
┌─────────── remainder
2 ) 20 r0
10 r0
5 r1
2 r0
1 r1
0 stop
remainders bottom to top, 1 0 1 0 0 → 00010100
Example: Negative via Long Division
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Example, -20₁₀, target width 8 bits
Step A, abs value long divide
┌─────────── remainder
2 ) 20 r0
10 r0
5 r1
2 r0
1 r1
0 stop
unsigned, 10100 → pad to width → 00010100
Step B, invert bits
00010100 → 11101011
Step C, add 1
11101011 + 1 → 11101100
Result, -20₁₀ → 11101100₂
4-bit Table
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Decimal | Two’s Complement
--------------------------
7 | 0111
6 | 0110
5 | 0101
4 | 0100
3 | 0011
2 | 0010
1 | 0001
0 | 0000
-1 | 1111
-2 | 1110
-3 | 1101
-4 | 1100
-5 | 1011
-6 | 1010
-7 | 1001
-8 | 1000
Sequential Logic
DFF
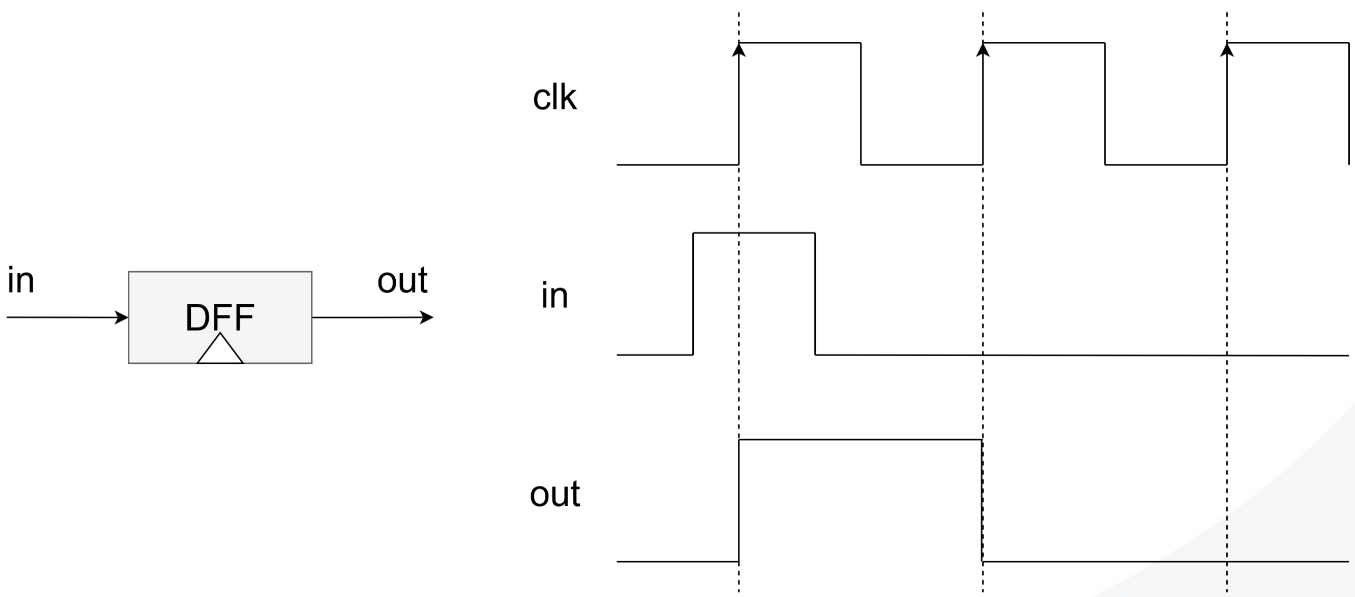
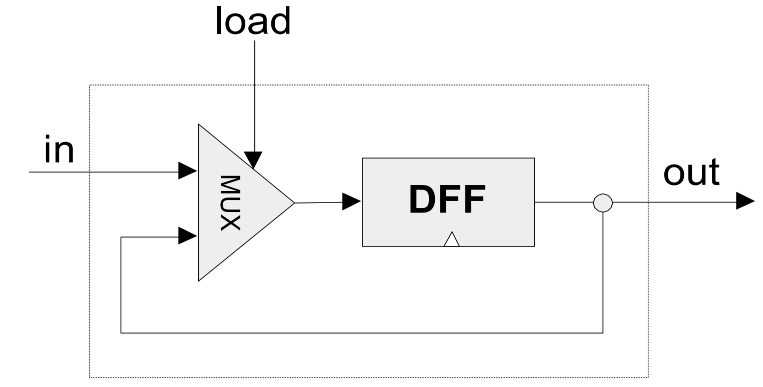
Bit (1-bit register)
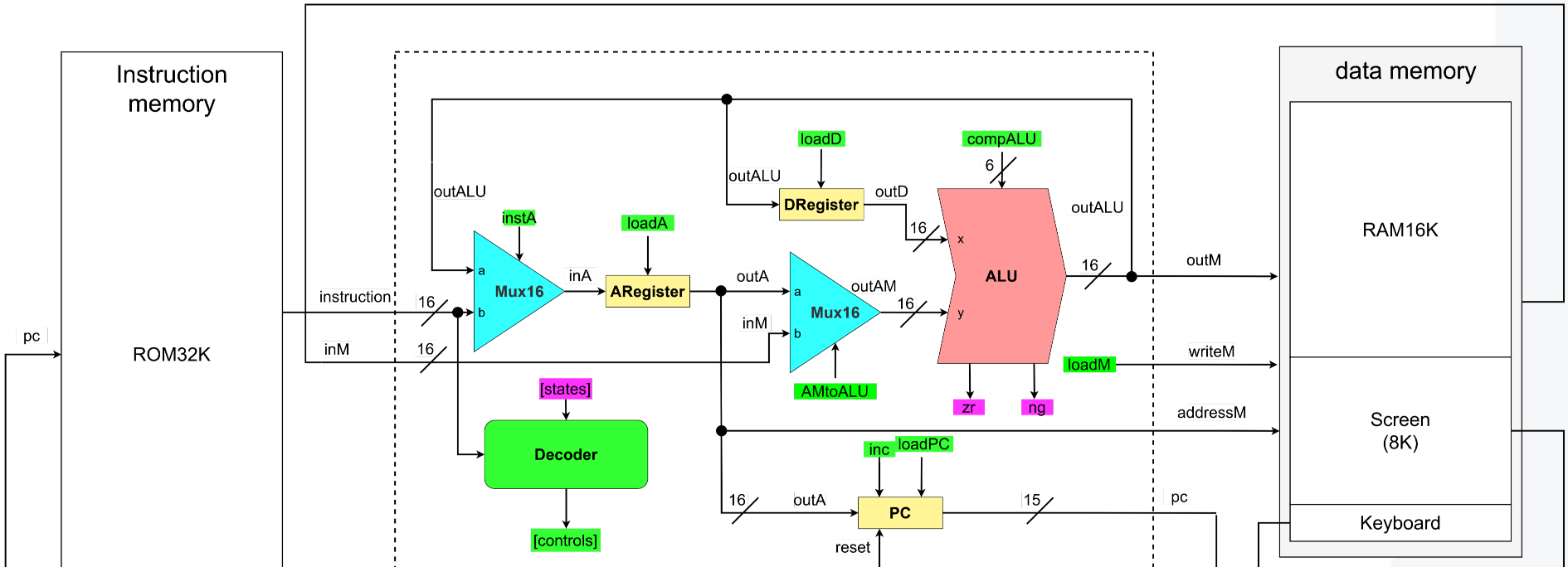
Computer Architecture
ALU
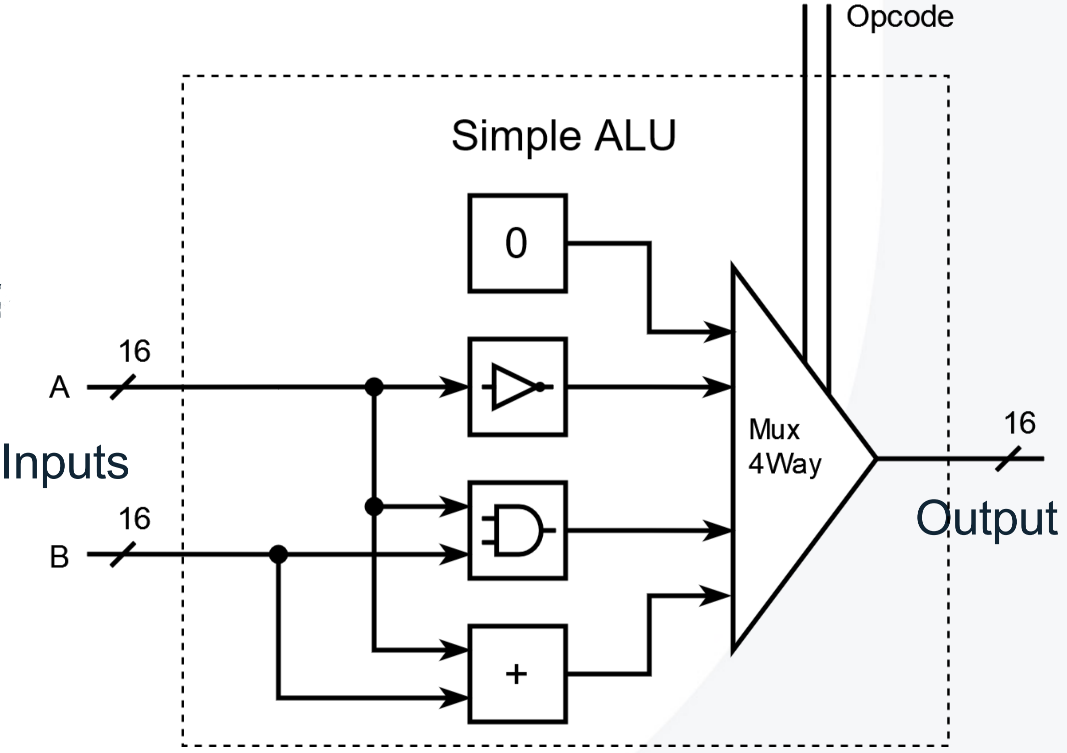
ALU Notes
- In two’s complement representation, the bitwise NOT operation $!y$ can be expressed as $!y = -y - 1$.
Assembly Language
Overview
The Hack assembly language contains two instruction types: A-instruction and C-instruction, plus labels for symbolic addresses. Each instruction is 16 bits long.
A-instruction
Form
1
2
@value
@symbol
Loads a constant or address into the A register. The value also becomes the memory address for M.
Example
1
2
3
4
@10
D=A
@counter
M=0
C-instruction
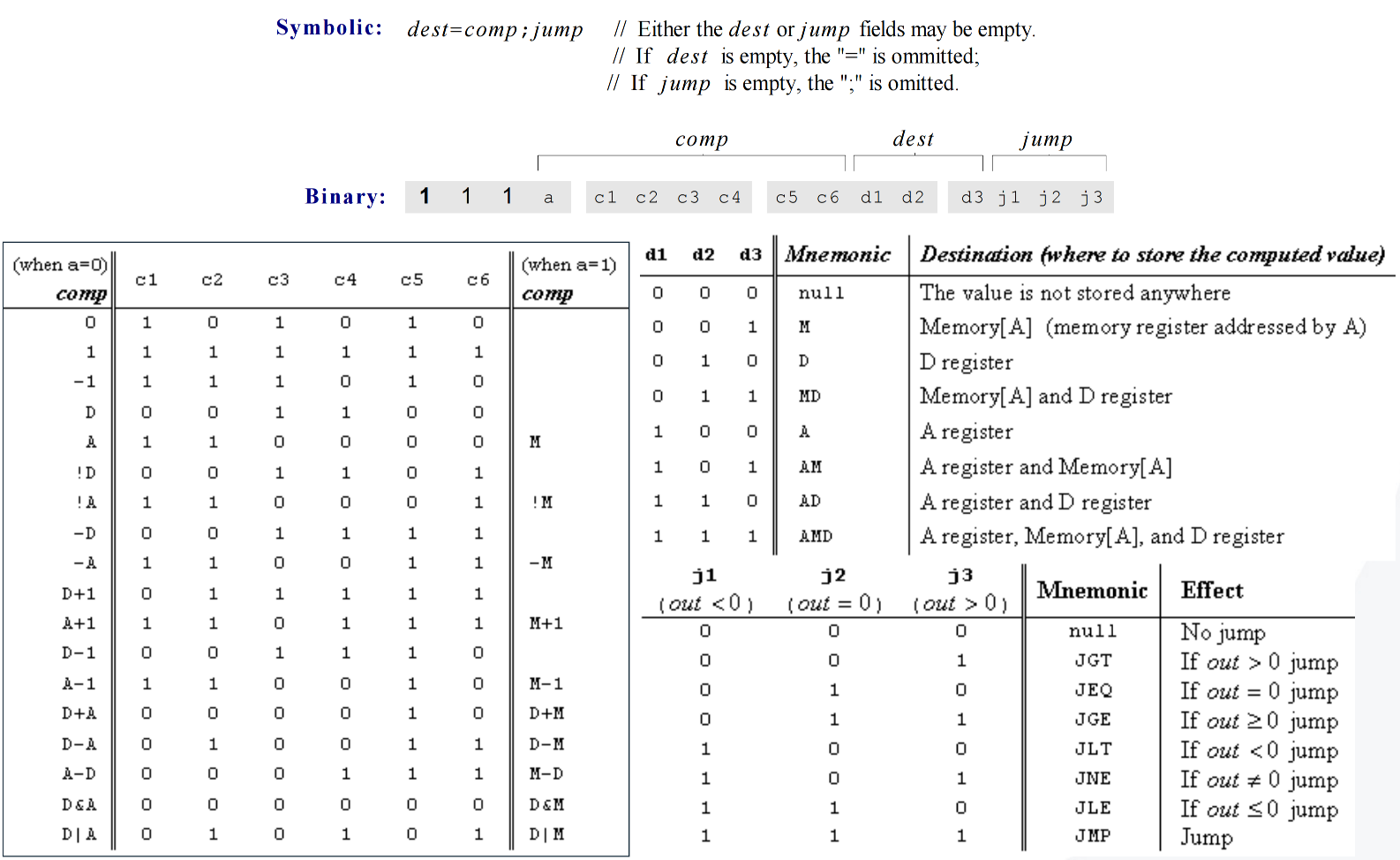
Form
1
dest=comp;jump
Performs computation and optionally stores or jumps.
dest: target (M, D, A, MD, AM, AD, AMD)comp: computation (ALU operation)jump: condition (JGT, JEQ, JGE, JLT, JNE, JLE, JMP)
Example
1
2
3
D=M
D;JGT
0;JMP
Common comp Values
1
2
3
4
5
0, 1, -1
D, A, M, !D, !A, !M, -D, -A, -M
D+1, A+1, M+1, D-1, A-1, M-1
D+A, D+M, D-A, D-M, A-D, M-D
D&A, D&M, D|A, D|M
Labels and Symbols
Label Declaration
1
(LOOP)
Marks a location. The label’s value is the address of the next instruction.
Predefined Symbols
| Symbol | Address | Meaning |
|---|---|---|
| SP | 0 |
Stack pointer (top of the stack) |
| LCL | 1 |
Base address of the local segment |
| ARG | 2 |
Base address of the argument segment |
| THIS | 3 |
Base address of the this segment |
| THAT | 4 |
Base address of the that segment |
| R0–R15 | 0–15 |
General purpose registers, aliases for the first 16 RAM addresses |
| temp (R5–R12) | 5–12 |
Fixed temporary segment, used for intermediate storage |
| pointer (THIS/THAT) | 3–4 |
Pointer segment that maps to THIS (0) and THAT (1) |
| static (FileName.index) | 16+ |
Static variables unique to each .vm file, starting from RAM[16] |
| SCREEN | 16384 |
Base address of the screen memory (for display pixels) |
| KBD | 24576 |
Address of the keyboard memory-mapped register |
Variables (custom symbols) start from address 16.
Example Program: Sum 1+2+…+n
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@i
M=0
@sum
M=0
(LOOP)
@i
D=M
@n
D=D-M
@END
D;JGT
@i
D=M
@sum
M=M+D
@i
M=M+1
@LOOP
0;JMP
(END)
Quick Reference
@value: load Adest=comp;jump: compute and control flow- Symbols: variables and labels
- Memory map: R0–R15, SCREEN(16384), KBD(24576)
ASM Notes
- First pass: Strip whitespace/comments, walk instructions to build the label table; each non-label command bumps the ROM address counter, while
(LABEL)entries alias the next instruction line. - Second pass: Revisit the cleaned instruction stream, resolve symbols (allocating RAM addresses from 16 upward for new variables), and emit the 16-bit Hack opcodes for every A- and C-instruction.
The following can be considered at the software level while the upper part is at the hardware level.
Virtual Machine Language
The VM language is a stack-based intermediate language that abstracts away hardware details. It describes computation using stack operations, memory access, branching, and function calls.
Stack and SP
The stack starts at address 256. The SP (Stack Pointer) always points to the next free slot.
pushwrites to*SP, thenSP = SP + 1popdecrementsSP, then reads from*SP
1
2
3
4
5
6
7
8
9
10
11
// push D onto stack
@SP
A=M
M=D
@SP
M=M+1
// pop top of stack into D
@SP
AM=M-1
D=M
Memory Segments
| VM Segment | Meaning | Assembly Base | Address Computation | Example |
|---|---|---|---|---|
| argument | Function arguments | ARG |
A = M + index |
push argument 2 → *(ARG + 2) |
| local | Local variables of the current function | LCL |
A = M + index |
pop local 0 → *(LCL + 0) |
| this | “this” pointer area | THIS |
A = M + index |
push this 1 → *(THIS + 1) |
| that | “that” pointer area | THAT |
A = M + index |
pop that 2 → *(THAT + 2) |
| temp | Temporary storage (RAM[5–12]) | 5 |
A = 5 + index |
push temp 3 → @8 |
| pointer | Stores THIS and THAT pointers (RAM[3–4]) | 3 |
A = 3 + index |
pop pointer 0 → THIS = *(SP-1) |
| static | File-specific static variables | 16 |
@FileName.index |
push static 2 → @Foo.2 |
| constant | Immediate values, not in RAM | — | D = A |
push constant 7 → D = 7 |
Basic Syntax of VM Language
1
2
3
4
5
6
7
8
9
10
push constant i
push segment i
pop segment i
add | sub | neg | eq | gt | lt | and | or | not
label X
goto X
if-goto X
function f k
call f n
return
Translations from VM language to Assembly
The C++ VMTranslator writes structured templates for every VM command. Values destined for the stack are staged in D and finalised with the shared push tail:
1
2
3
4
@SP
AM=M+1
A=A-1
M=D
For pop commands targeting base-pointer segments, the absolute address is cached in R13 before the stack value is stored. The assembler snippets below use placeholders such as index and FunctionName that the translator substitutes at runtime.
push segment index
push constant index1 2 3 4 5 6
@index D=A @SP AM=M+1 A=A-1 M=D
push local|argument|this|that index1 2 3 4 5 6 7 8 9
@index D=A @SEG // SEG ∈ {LCL, ARG, THIS, THAT} A=M+D D=M @SP AM=M+1 A=A-1 M=Dpush pointer 0|11 2 3 4 5 6
@THIS|THAT D=M @SP AM=M+1 A=A-1 M=D
push temp index1 2 3 4 5 6 7 8 9
@index D=A @5 A=D+A D=M @SP AM=M+1 A=A-1 M=D
push static index1 2 3 4 5 6 7 8 9
@index D=A @16 A=D+A D=M @SP AM=M+1 A=A-1 M=D
pop segment index
pop local|argument|this|that index1 2 3 4 5 6 7 8 9 10 11 12
@index D=A @SEG // SEG ∈ {LCL, ARG, THIS, THAT} D=M+D @13 M=D @SP AM=M-1 D=M @13 A=M M=Dpop pointer 01 2 3 4 5
@SP AM=M-1 D=M @THIS M=D
pop pointer 11 2 3 4 5
@SP AM=M-1 D=M @THAT M=D
pop temp index1 2 3 4 5 6 7 8 9 10 11 12
@index D=A @5 D=D+A @13 M=D @SP AM=M-1 D=M @13 A=M M=D
pop static index1 2 3 4 5 6 7 8 9 10 11 12
@index D=A @16 D=D+A @13 M=D @SP AM=M-1 D=M @13 A=M M=D
Arithmetic and logic
add
1
2
3
4
5
@SP
AM=M-1
D=M
A=A-1
M=M+D
sub
1
2
3
4
5
@SP
AM=M-1
D=M
A=A-1
M=M-D
neg
1
2
3
@SP
A=M-1
M=-M
and
1
2
3
4
5
@SP
AM=M-1
D=M
A=A-1
M=M&D
or
1
2
3
4
5
@SP
AM=M-1
D=M
A=A-1
M=M|D
not
1
2
3
@SP
A=M-1
M=!M
Comparisons
eq, gt, and lt share a helper that emits unique labels (CMP_TRUE0, CMP_END0, …). Example output for eq:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@SP
AM=M-1
D=M
@SP
AM=M-1
D=M-D
@CMP_TRUE0
D;JEQ
D=0
@CMP_END0
0;JMP
(CMP_TRUE0)
D=-1
(CMP_END0)
@SP
AM=M+1
A=A-1
M=D
gt substitutes JGT and lt uses JLT in the conditional jump.
Branching commands
label X:(X)goto X:1 2
@X 0;JMP
if-goto X:1 2 3 4 5
@SP AM=M-1 D=M @X D;JNE
Function commands
function FunctionName nLocals
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
(FunctionName)
@nLocals
D=A
@13
M=D
(FunctionName$initLocalsLoop)
@13
D=M
@FunctionName$initLocalsEnd
D;JEQ
@SP
AM=M+1
A=A-1
M=0
@13
M=M-1
@FunctionName$initLocalsLoop
0;JMP
(FunctionName$initLocalsEnd)
call FunctionName nArgs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
@FunctionName$ret.0 // counter increments per call site
D=A
@SP
AM=M+1
A=A-1
M=D
@LCL
D=M
@SP
AM=M+1
A=A-1
M=D
@ARG
D=M
@SP
AM=M+1
A=A-1
M=D
@THIS
D=M
@SP
AM=M+1
A=A-1
M=D
@THAT
D=M
@SP
AM=M+1
A=A-1
M=D
@SP
D=M
@5
D=D-A
@nArgs
D=D-A
@ARG
M=D
@SP
D=M
@LCL
M=D
@FunctionName
0;JMP
(FunctionName$ret.0)
return
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
@LCL
D=M
@13
M=D // frame = LCL
@5
A=D-A
D=M
@14
M=D // ret = *(frame-5)
@SP
AM=M-1
D=M
@ARG
A=M
M=D // *ARG = pop()
@ARG
D=M+1
@SP
M=D // SP = ARG + 1
@13
AM=M-1
D=M
@THAT
M=D
@13
AM=M-1
D=M
@THIS
M=D
@13
AM=M-1
D=M
@ARG
M=D
@13
AM=M-1
D=M
@LCL
M=D
@14
A=M
0;JMP // goto ret
R13 and R14 serve as the frame scratch space and cached return address.
Program Control
Subroutines & Functions
Stack Implementation
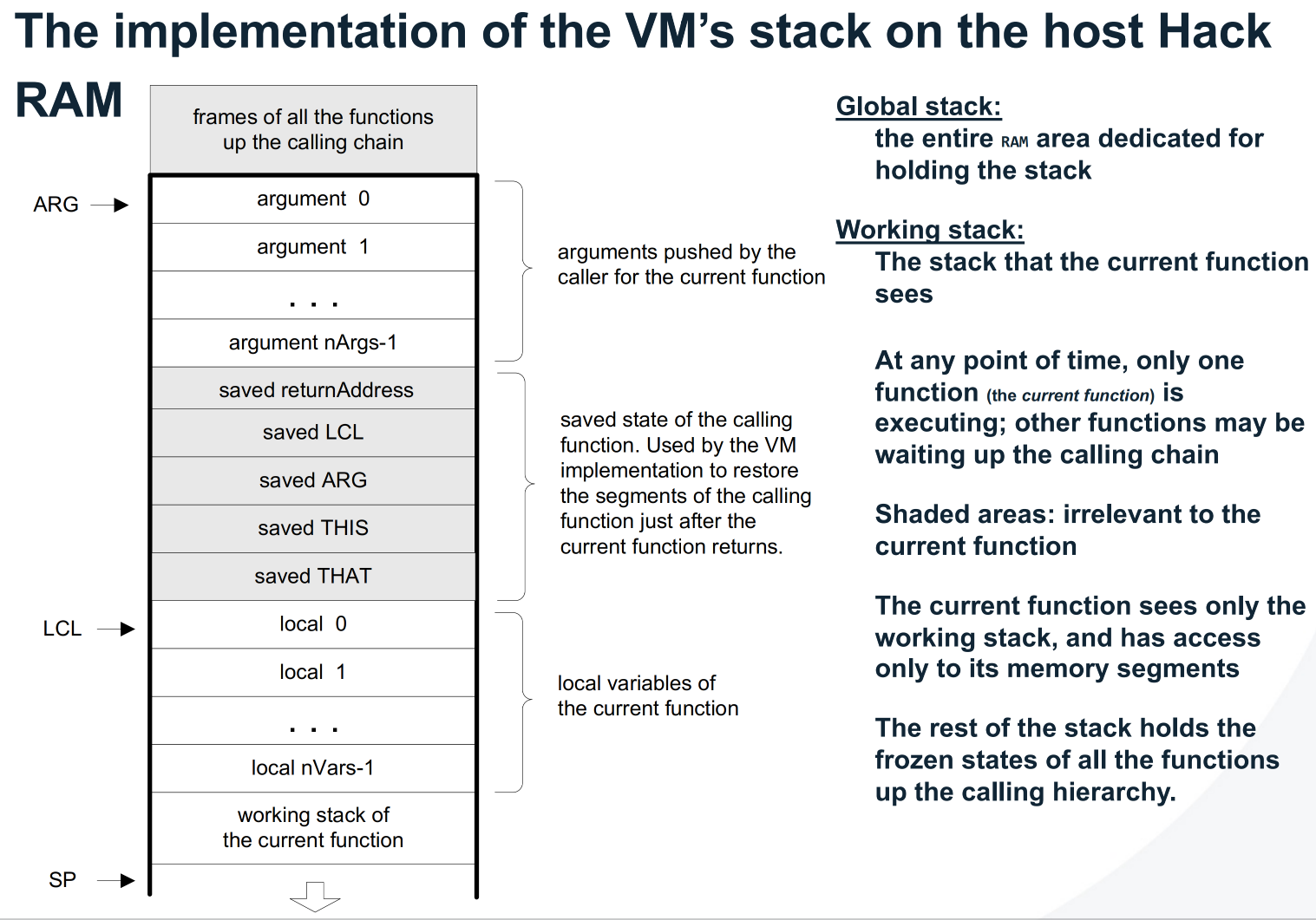
Call Implementation

Function Implementation

Return Implementation

Memory Architecture of the Hack Virtual Machine
The Hack Virtual Machine is implemented on a stack-based architecture. All function calls, arguments, and local variables are stored in the RAM. The CPU executes instructions fetched from the ROM, while the stack resides in RAM starting at address 256. The following diagram summarises the relationship between ROM, RAM, and the stack pointer segments.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
┌──────────────────────────────────────────┐
│ HACK CPU │
│──────────────────────────────────────────│
│ Registers: │
│ A → Address register │
│ D → Data register │
│ PC → Program counter │
│ │
│ Control signals: use A/D/PC to access │
│ RAM or ROM │
└──────────────────────────────────────────┘
│
│ (A register provides address)
▼
┌───────────────────────────────────────────┐
│ ROM │
│───────────────────────────────────────────│
│ Stores machine code (.hack instructions) │
│ Loaded from compiled .asm file │
│ PC fetches sequentially │
│ Read-only memory │
└───────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────┐
│ RAM │
│───────────────────────────────────────────│
│ Address range: 0 - 32767 │
│ │
│ 0–15 : General-purpose registers │
│ ├─ R0 = SP (Stack Pointer) │
│ ├─ R1 = LCL (Local segment base) │
│ ├─ R2 = ARG (Argument segment base) │
│ ├─ R3 = THIS (This segment base) │
│ ├─ R4 = THAT (That segment base) │
│ ├─ R5–R12 = Temp segment (8 slots) │
│ ├─ R13–R15 = General temporary registers│
│ │
│ 16–255 : Static variables (per file) │
│ │
│ 256–2047 : Stack segment │
│ ↑ │
│ │ push → write at stack top │
│ │ pop → remove from stack top │
│ │ SP points to next free slot │
│ │-------------------------------------- │
│ │ ← Stack base (256) │
│ │ [Return address] │
│ │ [Saved LCL, ARG, THIS, THAT] │
│ │ [Local variables local 0..n] │
│ │ [Working stack / evaluation values] │
│ │-------------------------------------- │
│ ↓ │
│ │
│ 2048–16383 : Heap / arrays / objects │
│ │
│ 16384–24575 : Screen memory map │
│ 24576–32767 : Keyboard input │
└───────────────────────────────────────────┘
VM Notes
- The VM provides portability by hiding the Hack memory details.
- SP management ensures correct push/pop order.
- Always use unique labels for comparisons and calls.
- ROM addresses are just sequential instruction numbers; label declarations don’t consume addresses, they alias the next instruction’s line number.
call: push return address and segment pointers, then jump to function.return: restore caller frame, repositionSP, and jump back to return address.- No
constantin pop operation.
High-Level Language (Jack)
Jack source compiles to VM commands, VM maps to Hack assembly.
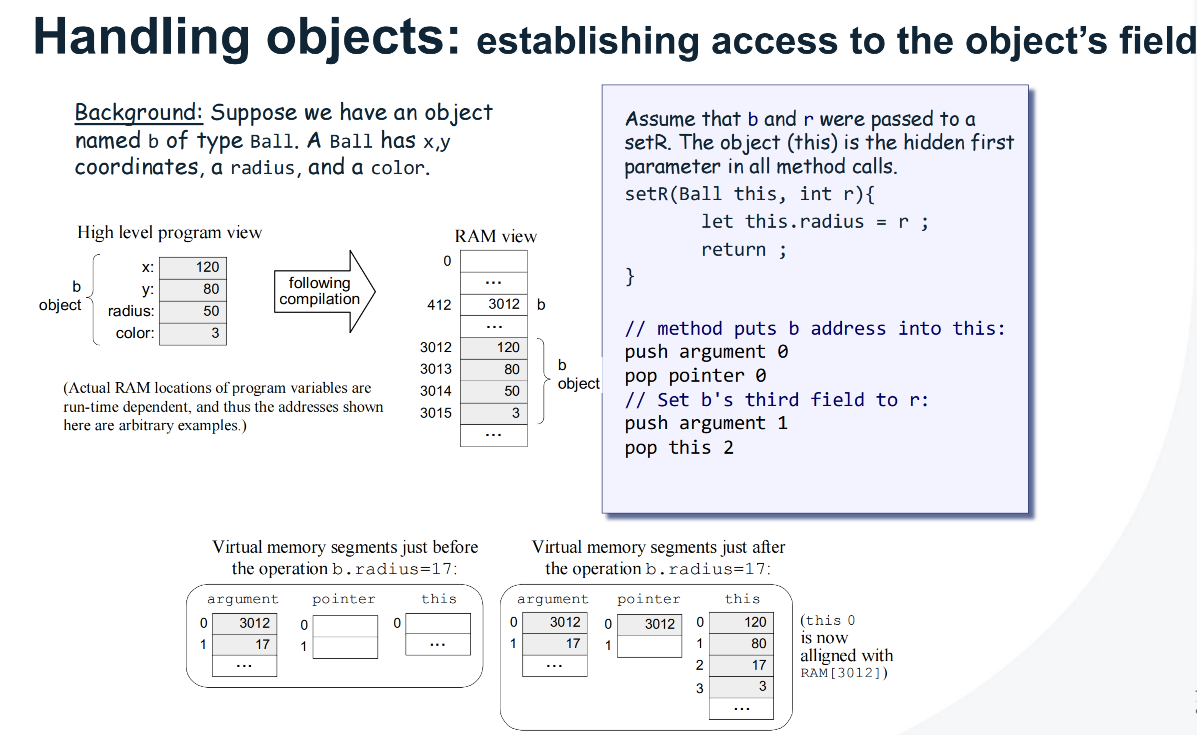
Segment Mapping
| Jack variable kind | VM segment | Notes |
|---|---|---|
| static | static | Per class file scope |
| field | this | Base in pointer 0 |
| var, local | local | Subroutine private |
| argument | argument | Call site provided |
| array base | this or local or argument | Depends on declaration |
Subroutine Kinds
| Jack subroutine | VM header | Entry actions |
|---|---|---|
| function | function ClassName.func k | No implicit this |
| method | function ClassName.method k | push argument 0, pop pointer 0 |
| constructor | function ClassName.new k | push constant fieldCount, call Memory.alloc 1, pop pointer 0 |
Statements, minimal templates
- let x = expr
1 2
... code for expr pop segment index // x
- let a[i] = expr
1 2 3 4 5 6 7 8
... code for a ... code for i add ... code for expr pop temp 0 pop pointer 1 push temp 0 pop that 0
- y = a[i]
1 2 3 4 5 6
... code for a ... code for i add pop pointer 1 push that 0 ... assign to y via pop segment index
- do subCall(args)
1 2 3 4
... push object ref if method call ... push args call QualName nArgs pop temp 0 // discard return
- if (cond) { S1 } else { S2 }
1 2 3 4 5 6 7 8 9
... code for cond if-goto IF_TRUE$n goto IF_FALSE$n label IF_TRUE$n ... S1 goto IF_END$n label IF_FALSE$n ... S2 label IF_END$n
- while (cond) { S }
1 2 3 4 5 6 7
label WHILE_EXP$n ... code for cond not if-goto WHILE_END$n ... S goto WHILE_EXP$n label WHILE_END$n
- return, return expr
1 2
push constant 0 // void return
1 2
... code for expr return
Expressions, operators
| Jack | VM expansion |
|---|---|
| - x | neg |
| not x | not |
| x + y | add |
| x − y | sub |
| x & y | and |
| x | y | or |
| x < y | lt |
| x > y | gt |
| x = y | eq |
| x * y | call Math.multiply 2 |
| x / y | call Math.divide 2 |
Literals and keywords
| Jack | VM |
|---|---|
| integer n | push constant n |
| true | push constant 0, not |
| false, null | push constant 0 |
| this | push pointer 0 |
String literal “abc”
1
2
3
4
5
6
7
8
push constant 3
call String.new 1
push constant 97
call String.appendChar 2
push constant 98
call String.appendChar 2
push constant 99
call String.appendChar 2
Length first, then append each code point.
Calls, qualification
| Jack form | VM call name | Arg0 rule |
|---|---|---|
| obj.m(a,b) | ClassName.m | push obj reference then a,b |
| Class.f(a,b) | Class.f | no implicit object |
| m(a,b) inside a method | ClassName.m | push pointer 0 then a,b |
Label policy
Use per subroutine counters, labels must be unique per function, for example IF_TRUE$n, WHILE_END$n.
Code Generation
Handling Objects

Handling Arrays
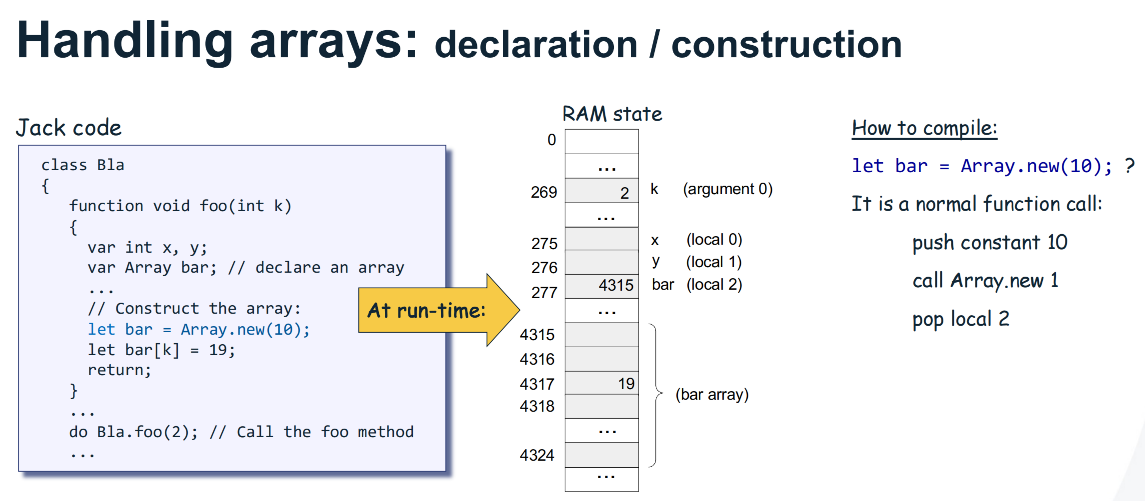
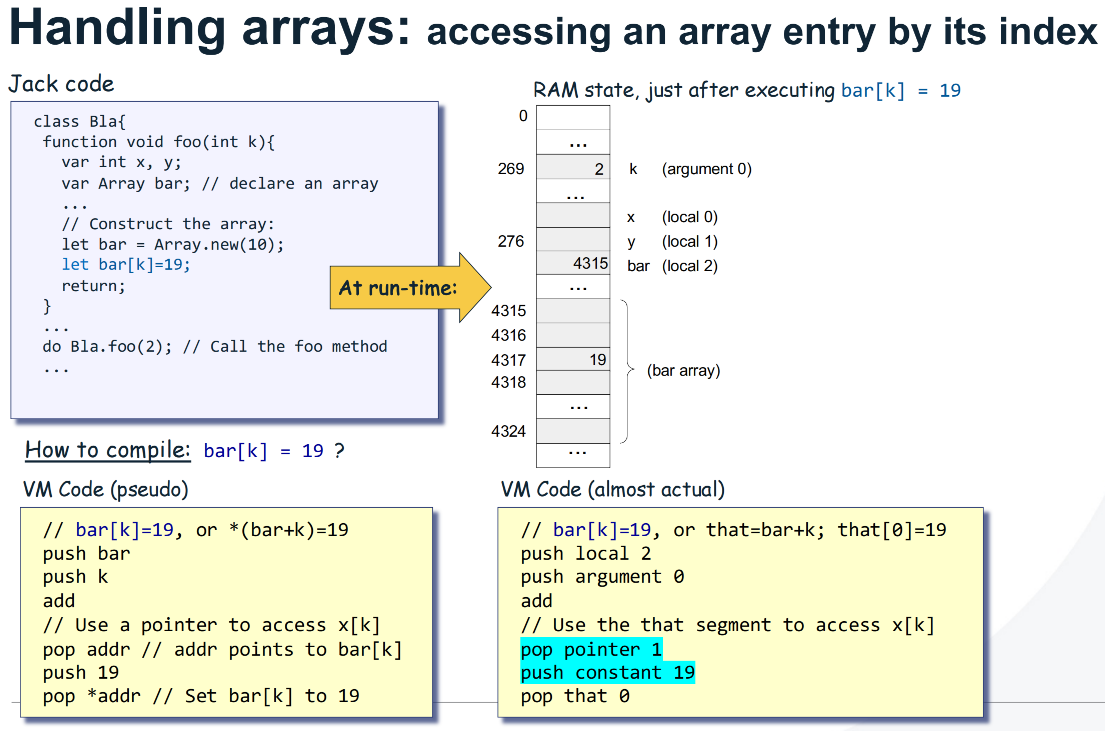
Example